Inspired by a tweet from Albert Lyu, I recently discovered the Gameday site that hosts PITCHf/x and other play-by-play data also has play-by-play for minor league games. The newest version of pitchRx has support to acquire play-by-play data from any minor league game. This post will show you how to go about doing that.
Gameday identifiers, revisited
In my last post, I discussed how to use gameday identifiers to acquire data for specific games. If you want minor league play-by-play data, you’ll have to use this approach. Just for demonstration purposes, consider the behavior of scrape when using a start and end date:
library(pitchRx)
dat <- scrape(start = "2012-01-01", end = "2013-01-01")This considers any game that a major league team played in during 2012 – even games between a major league and minor league team. We can replicate this result using gameday identifiers (that is, gids) instead.
data(gids, package = "pitchRx")
gids12 <- gids[grepl("2012", gids)]
dat <- scrape(game.ids = gids12)gids12[[1]]## [1] "gid_2012_02_29_fanbbc_phimlb_1"The first element of gids12 identifies a game between the Florida State University Seminoles (which has a team code of ‘fan’) and the Philadelphia Phillies (which has a team code of ‘phi’). The ‘bbc’ bit after ‘fan’ is a league code that let’s us know that, in this case, the away team ‘fan’ is a college team. Similarly, the ‘mlb’ bit after ‘phi’ tells us the home team is an MLB team. To gain some insight on both the type and quantity of games by league type, consider the following:
league.away <- substr(gids12, 19, 21)
league.home <- substr(gids12, 26, 28)
leagues <- paste(league.away, league.home, sep = "-")
sort(table(leagues), decreasing = TRUE)## leagues
## mlb-mlb bbc-mlb mlb-aaa mlb-jml min-mlb mlb-aax aaa-mlb afa-mlb mlb-afa
## 2976 10 4 4 3 3 1 1 1This table shows there are nearly 3000 games between two major league teams in 2012 that are available for data aquisition and just a handful of games between a major and minor league team. As it turns out, there is a wealth of data on games between minor league teams. Here is a table of translations for all the league codes (thanks Albert and Harry):
| Code | Full name |
|---|---|
| aaa | Triple A |
| aax | Double A |
| afa | High A |
| afx | Low A |
| asx | Short Season A-ball |
| bbc | College |
| hsb | High School |
| int | World Baseball Classic |
| jml | Japanese |
| min | Generic Minors |
| mlb | Major League Baseball |
| nae | Junior National Team |
| nat | National Team |
| rok | Rookie Ball |
| win | Winter League |
Acquiring data from non-MLB games
As we’ve seen, the gids data object that comes packaged with pitchRx contains games with at least one MLB team, but what about non-MLB games? The new nonMLBgids object provides similar identifiers for non-MLB games which can be used to acquire data just like gids. For example, say I want any triple A game played on June 1st. First, let’s extract the appropriate set of identifiers from all the available identifiers:
data(nonMLBgids, package = "pitchRx")
aaa <- nonMLBgids[grepl("2011_06_01_[a-z]{3}aaa_[a-z]{3}aaa", nonMLBgids)]Now we just pass these gameday identifiers to scrape‘s game.ids argument. Note that we can also use the suffix argument in the usual way to acquire data from more file types than just the ’inning/inning_all.xml’ default.
dat <- scrape(game.ids=aaa, suffix=c("inning/inning_all.xml",
"inning/inning_hit.xml",
"players.xml",
"miniscoreboard.xml"))Since we specified ‘inning/inning_hit.xml’ in suffix, the ‘hip’ (hits-in-play) table is one of the many tables returned by scrape. Let’s use this data to plot all the hits in play on June 1st. This turns out to be very easy with some help from openWAR.
library(openWAR)
# 'recenter' hit locations
hip.day <- openWAR:::recenter(dat$hip)
class(hip.day) <- c("GameDayPlays", "data.frame")
names(hip.day) <- sub("des", "event", names(hip.day))
plot(hip.day)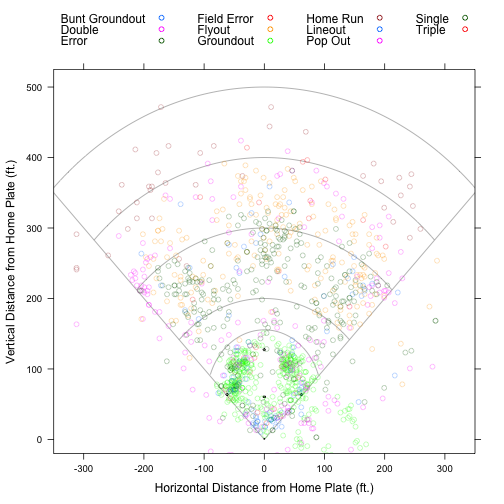
That’s a lot of games!
nonMLBgids contains roughly 5 times more identifiers than gids. To give an idea of the scale, remember that gids contained about 3000 identifiers from 2012, so nonMLBgids contains about 15000 identifiers from 2012.
nonMLB12 <- nonMLBgids[grep("2012", nonMLBgids)]
length(nonMLB12)And those non-MLB games from 2012 broken down by league type:
league.away <- substr(nonMLB12, 19, 21)
league.home <- substr(nonMLB12, 26, 28)
leagues <- paste(league.away, league.home, sep = "-")
sort(table(leagues), decreasing = TRUE)Building a non-MLB database
Since non-MLB games don’t have PITCHf/x, the columns required for the ‘pitch’ table is a subset of columns required for MLB games. This is just one reason why you probably want to keep you’re MLB tables separated from non-MLB tables. I think the easiest approach to just maintain another (nonMLB) database. Also, since nonMLBgids provides access to over 100,000 games, one should think carefully about which games they actually want/need. For instance, let’s start a database and fill it with every Triple A game.
library(dplyr)
db <- src_sqlite("nonMLB.sqlite3", create = TRUE)
# logical vector with TRUE if the home OR away league is Triple A
aaa <- grepl("[a-z]{3}aaa_[a-z]{6}", nonMLBgids) | grepl("[a-z]{6}_[a-z]{3}aaa", nonMLBgids)
aaaGids <- nonMLBgids[aaa]
# DISCLAIMER: This scrapes a lot of games! Be patient!
scrape(game.ids = nonMLBgids, connect = db$con)